
Sample Ratings
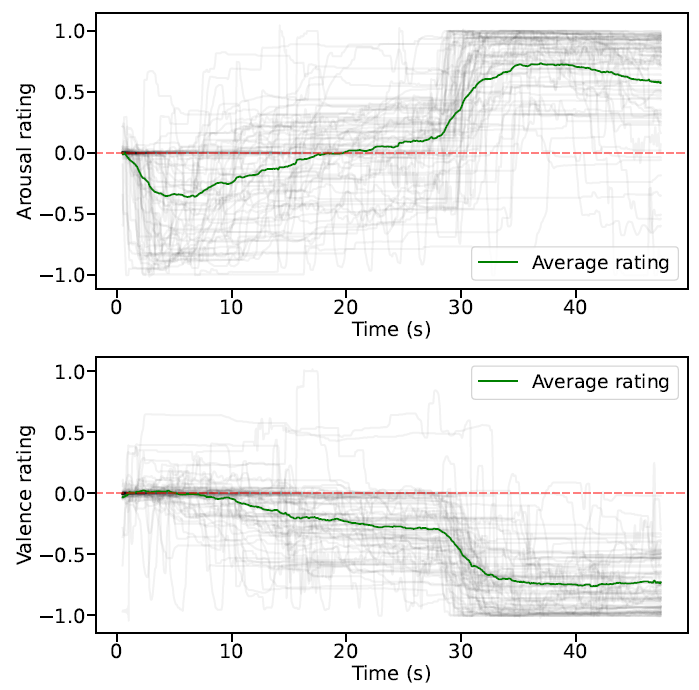
Example valence and arousal ratings for a single video (video 47). Transparent gray lines indicate individual subject ratings and the green line is the average rating across participants.
Human affect recognition has been a significant topic in psychophysics and computer vision. However, the currently published datasets have many limitations. For example, most datasets contain frames that contain only information about facial expressions. Due to the limitations of previous datasets, it is very hard to either understand the mechanisms for affect recognition of humans or generalize well on common cases for computer vision models trained on those datasets. In this work, we introduce a brand new large dataset, the Video-based Emotion and Affect Tracking in Context Dataset (VEATIC), that can conquer the limitations of the previous datasets. VEATIC has 124 video clips from Hollywood movies, documentaries, and home videos with continuous valence and arousal ratings of each frame via real-time annotation. Along with the dataset, we propose a new computer vision task to infer the affect of the selected character via both context and character information in each video frame. Additionally, we propose a simple model to benchmark this new computer vision task. We also compare the performance of the pretrained model using our dataset with other similar datasets. Experiments show the competing results of our pretrained model via VEATIC, indicating the generalizability of VEATIC.
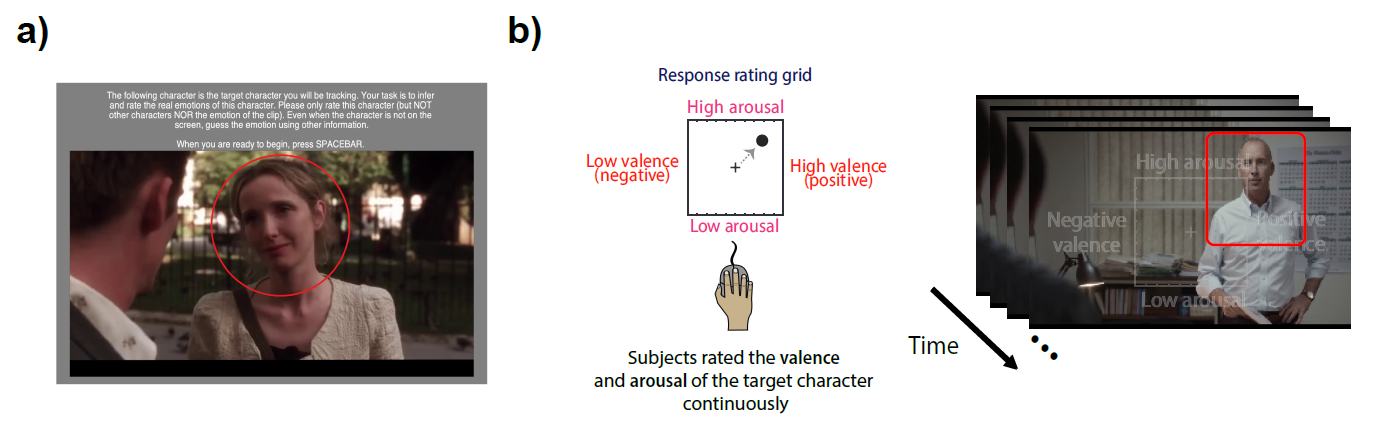
User interface used for video annotation. a) Participants were first shown the target character and were reminded of the task instructions before the start of each video. b) The overlayed valence and arousal grid that was present while observers annotated the videos. Observers were instructed to continuously rate the emotion of the target character in the video in real-time.
Example valence and arousal ratings for a single video (video 47). Transparent gray lines indicate individual subject ratings and the green line is the average rating across participants.
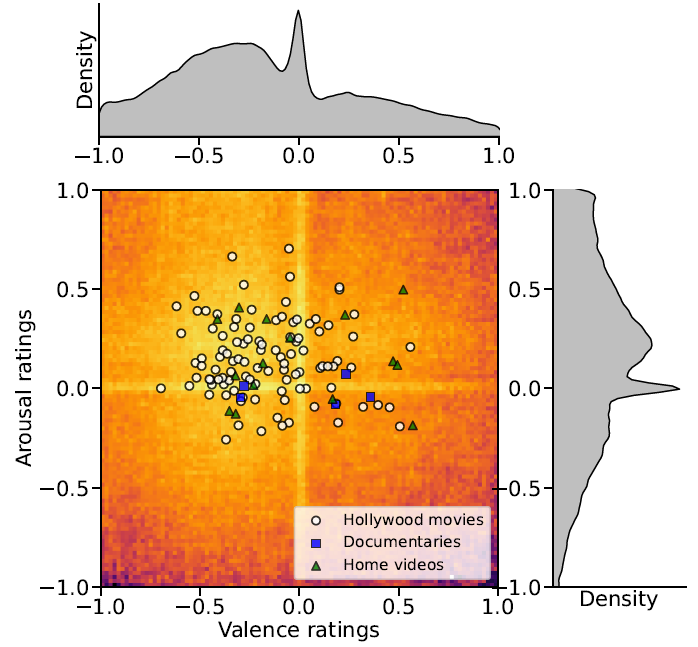
Distribution of valence and arousal ratings across participants. Individual white dots represent the average valence and arousal of the continuous ratings for each video clip for Hollywood movies. Blue squares and green triangles represent the average valence and arousal for documentaries and home videos, respectively.
VEATIC is available to download for research purposes.
The copyright remains with the original owners of the video.
This benchmark contains 124 annotated videos.
For each video, the first 70% of the frames are for training and the rest 30% of the frames are for testing. You can directly utilize the dataset class provided in our baseline repository for training and testing your own model.
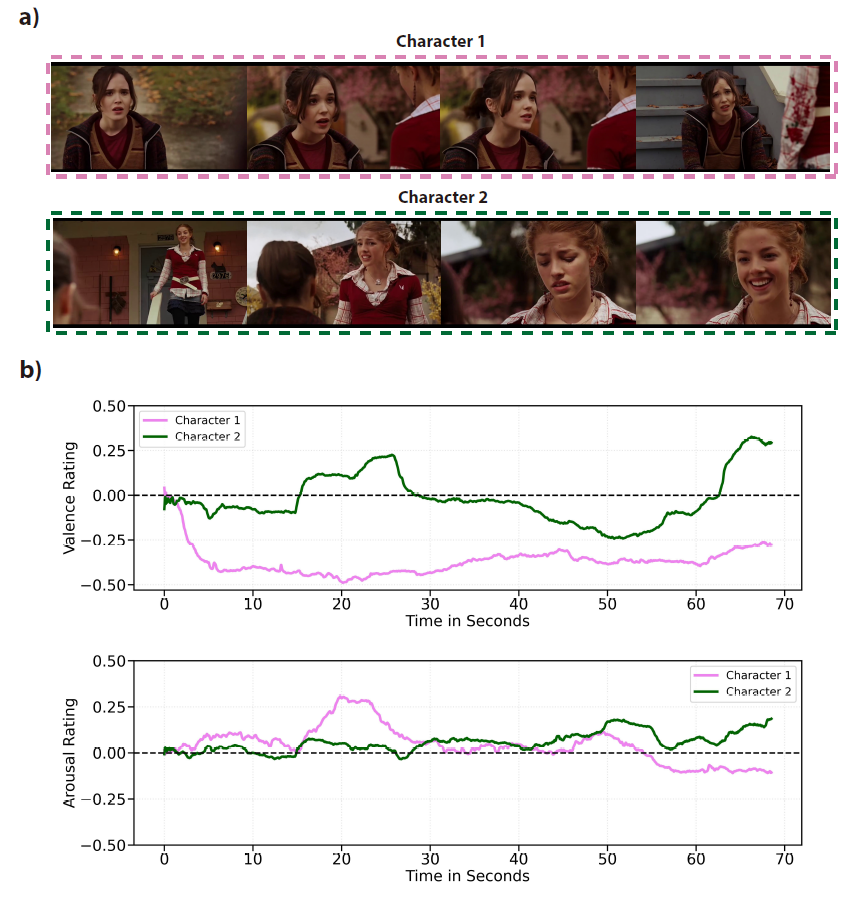
VEATIC also contains videos with interacting characters and ratings for separate characters in the same video. These videos are those with video IDs 98-123.
We also provide individual ratings of each video with video IDs 0-82 for psychophysical studies. These ratings can be found below. Each column of a file represents one individual's ratings, and same individuals can be identified via their ID markers.
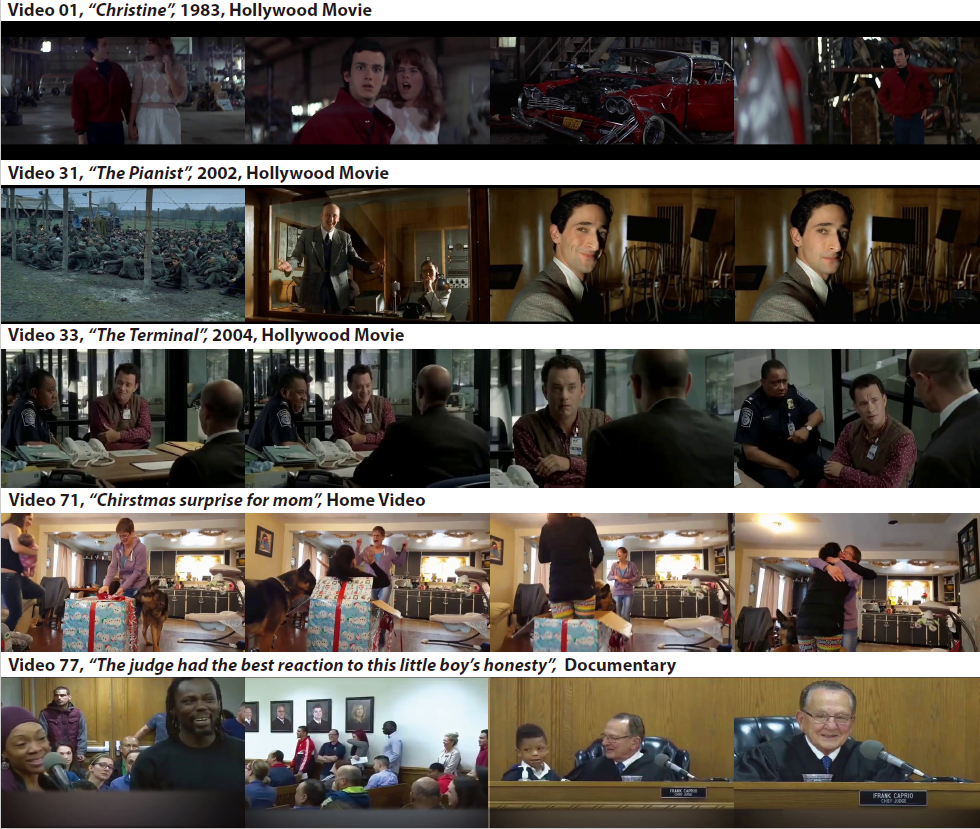
You can find the target characters of each video below. We circled out the target character with a red circle in a frame of each video.
@inproceedings{ren2024veatic,
title={VEATIC: Video-based Emotion and Affect Tracking in Context Dataset},
author={Ren, Zhihang and Ortega, Jefferson and Wang, Yifan and Chen, Zhimin and Guo, Yunhui and Yu, Stella X and Whitney, David},
booktitle={Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision},
pages={4467--4477},
year={2024}
}